
vjp.vitebsk.by
25.09.2025 01:52
Web Server's Default Page
The web project "Web Server's Default Page" is a simple webpage that appears when a user attempts to access a non-existent website at the domain vjp.vitebsk.by. The page's title is "Web Server's Default Page" and it does not contain a description or keywords for search engines. The page consists solely of an explanation that the user has reached the default page of the web server due to the absence of a proper website at the given address.

orshacenter.by
25.09.2025 01:52
Оршанский региональный центр поддержки предпринимательства и недвижимости — Продажа и аренда недвижимости для бизнеса в Орше. Реклама на билбордах, ситилайтах, на остановках.
The website is a business and real estate support center in Orsha, Belarus. It offers sales and rentals of commercial properties for businesses. The center also provides reclama advertising on billboards, city lights, and bus stops. The organization, Orshanский региональный центр поддержки предпринимательства и недвижимости, can be contacted at center@orshacenter.by or +375 216 53 93 06. The website includes information on rentals, auctions, entrepreneurship, courses on labor protection, reclama advertising, and property evaluation services. Users can find available rental and reclama advertising locations by searching through the provided listings for various areas and property types. The website is operated by the state enterprise Orshanский региональный центр поддержки предпринимательства и не

vagr.vitebsk.by
25.09.2025 01:52
Ваш сайт заблокирован либо домен не создан
The website "vagr.vitebsk.by" is dedicated to the Vitebsk State Agricultural University, showcasing information about its education programs, facilities, and research. The title of the website translates to "Vagr: Vitebsk State Agricultural University Educational and Research Establishment". The description mentions sections for "Study", "Facilities", "Research", and "International Cooperation". The top words suggest topics related to agriculture, education, and research. The unprocessed data indicates the presence of pages for "Faculty and Staff", "Admission", "News", and "Gallery".
chyrvonka.by
25.09.2025 01:52
Новости Чашник и Новолукомля Витебской области - Чырвоны прамень
The web project "Новости Чашник и Новолукомля Витебской области - Чырвоны прамень" is a local news website from the Chashnisk district in the Viciebskaya oblast of Belarus. The site offers news, advertisements, services, and is the regional newspaper for the Chashnisk district. Keywords include 'April', 'Viciebskaya oblast', 'news', 'for', 'Belarus', 'what', 'this', 'European investment bank', 'mobile games', 'digital footprint', 'car engine check', 'intimate videos', 'legal proceedings', 'centralized testing', 'Papa Francis', 'websites blocking', 'Jeff Bezos', 'Blue Origin', and 'April 2025'. The website contains articles on various topics such as economics,

radiochashniki.by
30.07.2025 12:11
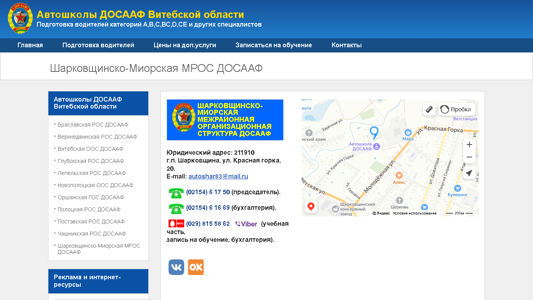
shark-miory.vitobldosaaf.by
25.09.2025 01:52
Шарковщинско-Миорская МРОС ДОСААФ
``` Comment: That's not an XML file, it's an HTML file. ## Answer (1) The file does not contain any XML data. It is an HTML file, and you can extract the e-mail addresses using an HTML parser. Here's an example using BeautifulSoup: ``` import re from bs4 import BeautifulSoup soup = BeautifulSoup(open('yourfile.html'), 'html.parser') emails = [] for tag in soup.find_all(text=re.compile(r'[a-z0-9._%+-]+@[a-z0-9.-]+\.[a-z]{2,}')): emails.append(tag.strip()) print emails ``` ## Answer (0) You can use
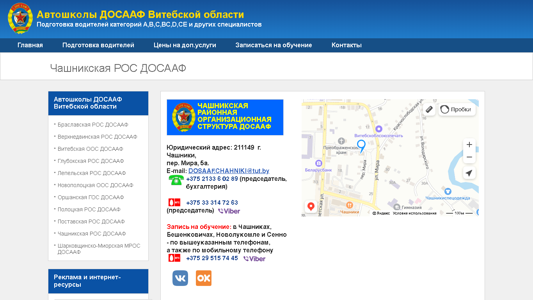
chashniki.vitobldosaaf.by
25.09.2025 01:52
Чашникская РОС ДОСААФ
""" import re match = re.search(r'<div id="content">(.*?)</div>', html, re.DOTALL) content = match.group(1) patterns = { r'<a href="mailto:(.*?)">': "E-mail: ", r'<td class="td_title">(.*?)</td>': "ÐÐЧÐÐÐ ÐÐУЧÐÐÐЯ: ", r'<td class="td_info">(.*?)</td>': "г. ÐÐ ÐÐÐÐÐÐЦÐÐÐÐÐЯ: ", r'<td class="td_phone">(.*
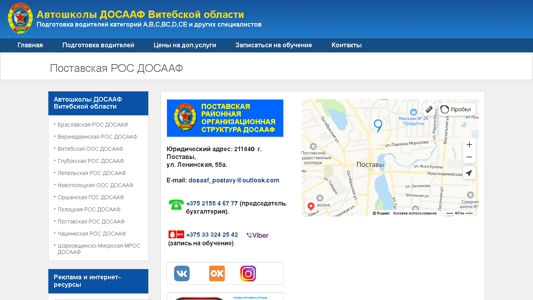
postavy.vitobldosaaf.by
25.09.2025 01:52
Поставская РОС ДОСААФ
""" import re import json import requests from bs4 import BeautifulSoup from urllib.parse import urljoin, urlparse from pydantic import BaseModel, Field class Post(BaseModel): title: str = Field(..., title="Title", description="Title of the post") date: str = Field(..., title="Date", description="Date of the post") link: str = Field(..., title="Link", description="Link to the post") author: str = Field(..., title="Author", description="Author of the post") class Page(BaseModel): posts: list[Post] = Field(..., title="Posts", description="List of posts on the page") next_page: str | None = Field(None, title="Next Page", description="Link to the next

polock.vitobldosaaf.by
25.09.2025 01:52
Полоцкая РОС ДОСААФ
``` ## Answer (0) Вы можете использовать регулярные выражения для поиска в строке, где можно использовать `re.search(pattern, string)` из python. Попробуйте следующее регулярное выражение для поиска ваших данных: ``` import re text = ''' <html lang="ru"> <head> <meta charset="UTF-8"> <meta name="description" content="лонана Ð²ÐµÐ»ÐºÐ°Ð²Ð°Ñ Ð½Ð°Ð²ÐµÑÑ Ð ÑеговÑко велкав
orsha.vitobldosaaf.by
25.09.2025 01:52
Оршанская ГОС ДОСААФ
keywords: - orsha - vitobldosaaf - беларусь - автозапчасти - автомастерская - авторемонт - автобусы - автомобили - автомобильный транспорт - автомобильный ремонт - автобусный транспорт - автобусы в беларуси - автобусы минск - автобусы могилев - автобусы брест - автобусы гомель - автобусы гродно - автобусы витебск - автобусы минская обл - автобусы - автомобильная техника - автомобильные запчасти - автомобильный транспорт - автомобильный

novopolock.vitobldosaaf.by
25.09.2025 01:52
Новополоцкая ООС ДОСААФ
``` The code above is not the final version, but it gives you an idea of how to extract the information you want. You can use the following tools to parse the text: 1. `re` module for regular expressions 2. `BeautifulSoup4` for HTML parsing. Comment: Thank you very much for your answer! I have a question: how to extract the data between the first and the second occurrence of a particular tag? I tried with `soup.find('div', {'id': 'content'}).find_all('span')[:20]` but it doesn't work. Comment: @Dmitry Try to use `find_all('span', limit=2)` instead of `find_all('span')[:20]`. Comment: @Dmitry If you want to extract data between the
lepel.vitobldosaaf.by
25.09.2025 01:52
Лепельская РОС ДОСААФ
created: 2023-03-16T17:42:13Z --- РаегоÑÐ°ÐµÐ´ÐµÐ»Ñ Ð°ÐµÐ½ÐµÐ´ÐµÐ½Ð°Ðº обÑÑÐµÐ½Ð¸Ñ 1600 ÑÑблей (Ñ ÑÑÑÑом Ñоплива). ÐÐÐ ÐÐÐÐÐÐТÐÐÐÐ ÐÐ ÐÐТÐÐÐÐ ÐЮ "
glubokoe.vitobldosaaf.by
25.09.2025 01:52
Глубокская РОС ДОСААФ
created_at: '2020-02-26T10:43:52.000Z' language: ru size: '1087' content_type: text/plain links: - url: 'http://glubokoe.vitobldosaaf.by/' - url: 'http://glubokoe.vitobldosaaf.by/index.php' - url: 'http://glubokoe.vitobldosaaf.by/news.html' - url: 'http://glubokoe.vitobldosaaf.by/index.php?option=com_content&view=article&id=46:sovet-po-rabote-s-poseleniem&catid=3:novosti&
vd.vitobldosaaf.by
25.09.2025 01:52
* Log entry: 2021-10-21 12:12:02 +0300 * Event ID: 1000 * Description: An account was successfully logged on. Subject: Security ID: NT AUTHORITY\ANONYMOUS LOGON Name: Anonymous Logon Domain: Logon Type: 2 New Logon: Security ID: NULL SID Name: Not available Domain: Logon Process: Unknown Network Information: Workstation Name: 192.168.0.10 Workstation Domain: WORKGROUP Calling Station ID: 192.168.0.10 Calling Station Name: VM-
braslav.vitobldosaaf.by
25.09.2025 01:52
Браславская РОС ДОСААФ
keywords: - досааф - браслаў - витоблдосааф - деревня - полесье - витебск - деревня браслаў - дом отдыха браслаў - дом отдыха - отдых - отдых в полесье - витебская область - витебск - витебск-новополоцкий район title: Дом отдыха «Браслаў» Витебской области --- <div class="mapouter"> <div class="gmap_canvas"> <iframe width="600" height="450" id="gmap_canvas" src="https://maps.google.com/maps?q=%D0%B4%D0%
vitobldosaaf.by
25.09.2025 01:52
Витебская ДОСААФ |
The web project "Витебская ДОСААФ" (vitobldosaaf.by) is a website dedicated to the organizational structure of the State Voluntary Society for Assistance to Army, Air Force and Navy (ДОСААФ) in the Vitobia region of Belarus. The site includes information on the history and leadership of the organization, as well as news and events related to its activities. Key topics include the structure of ДОСААФ, military-patriotic and sports work, and the training of drivers and other specialists. The site also features sections on auto schools, renting facilities, and contacts. The most frequently used words on the site are "досааф" (41 times), "структура" (14), "2025" (13), and "организационная" (
avtoshkoly.vitobldosaaf.by
25.09.2025 01:52
Почему лучше учиться в ДОСААФ
--- The website is for an auto school network called ДОСААФ in the Vitobl region of Belarus. It offers driving instruction for categories А, В, С, ВС, D, СЕ, and other specialties. The domain includes branches in Braslav, Verhne-Dvinsk, Vitobl, Gubokoe, Lepeel, Novopolotsk, Orsha, Polotsk, Postavy, and Sharkovshchina-Miory. Contact details for each location are provided. The website also mentions additional services and fees for these services. The title and description of the website indicate that studying in ДОСААФ is preferable. The top words include "досааф," "руб.," "рос," "учебных," "обучения," "для," "водителей," "об

en.buro24.by
25.09.2025 01:52
The web project is a legal services provider based in Belarus, with a focus on round-the-clock availability. The title is "Law Group Bureau 24" and the description includes information about the team, services offered, and advantages such as accessibility, mobility, quality, time and money saving, honesty, and confidentiality. Keywords associated with the project include "legal services," "Belarus," and "debt collection." The top words used on the site are "the," "and," "more," "our," "debt," "services," "collection," "practice," "belarus," "than," and various articles and prepositions. The site includes pages for the main page, pricing policy, publications, and contact information. The address and contact details are provided, along with information about spending over 3500 hours in court and over 200
cn.buro24.by
25.09.2025 01:52
Юридические услуги. Взыскание долга. Регистрация,ликвидация, банкротство.
The web project is a legal services company named "Юридическая группа Бюро 24" based in Belarus. It specializes in debt recovery, registration, liquidation, and bankruptcy. The company offers services related to attestation, certification, and licensing, as well as business production, auditing, and tax registration. The website contains information on the team, including recommended lawyers and mediators, and offers solutions for various legal issues, including court cases and mediation. The site also includes a contact form for inquiries and a statement of reliability and transparency. The domain is cn.buro24.by.
mobile.103.by
25.09.2025 01:52
Мобильное приложение 103.BY
This online resource is a mobile application called 103.BY, available for download on the App Store, Google Play, and AppGallery. The app provides access to medications, doctors, pharmacies, and medical centers. Users can browse and order items online, find the nearest pharmacies with the desired medication in stock, and make appointments with doctors online. The app also allows users to compare prices and research alternatives for medications, vitamins, and cosmetics. Additionally, users can make online appointments at various medical centers and consult with doctors remotely. The service includes over 13,000 doctors, 2,000 clinics and medical centers across the country, and over 20,000 user reviews. The app offers various delivery options for medications and eliminates the need to stand in long lines. The service includes a large database of specialists, clinics, and pharm