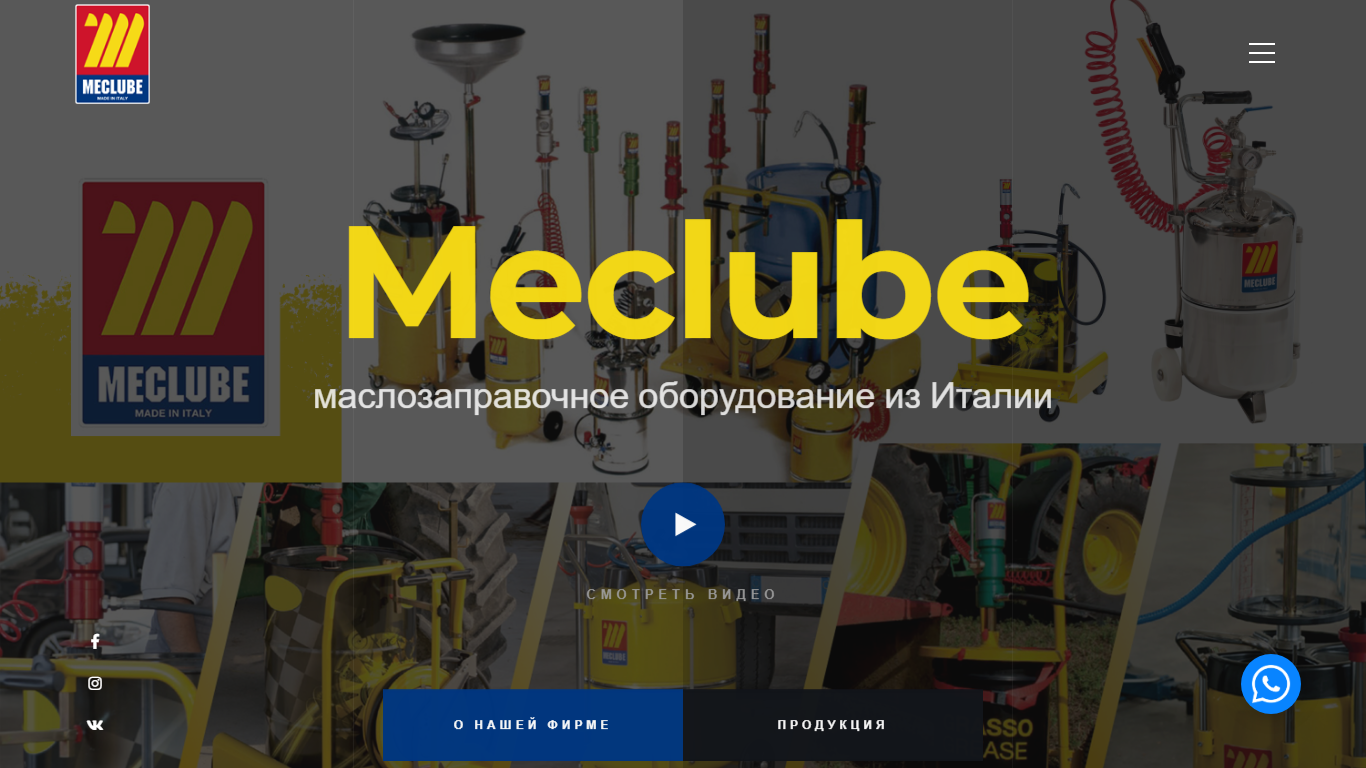
| Название / Заголовок | Маслозаправочное оборудование |
|---|---|
| Телефон | +375172801389, +375293452050, +375293253253, +375445335364, +375172921430 |
| belscorpio@mail.ru, 75b6a20df0014dbc8cf4d074eeeea6c5@stacks.vk-portal.net | |
| Адрес | ваши вопросы, по оборудованию Meclube., belscorpio@mail.ru, ОДО «Белскорпио», Республика Беларусь, ул. Чернышевского, 10а |
| Обновлено | 2026-05-27 00:13:43.383127+00 |
| IP адрес | 176.119.157.173 |
| Проверка IP | 2025-12-03 07:10:46.152523+00 |
| Canonical URL | https://vk.com/public172429182 |
| Viewport | width=device-width, initial-scale=1 |
| AI-анализ | The web project "Meclube.belscorpio.by" is an official distributor of the Italian Meclube company's oil pumping equipment in Belarus. With over 27 years of experience, they supply industries and service stations with high-quality Italian equipment for pumping thick oils, fuels, various types of lubricants, and other liquids of different viscosities. Meclube's equipment is considered among the best in the world and is used in many factories and plants. The equipment is used for draining oil and distributing lubricants at automotive service stations. Meclube produces a wide range of pumps that can handle: gasoline, diesel fuel, kerosene, lubricating oils, and other viscous liquids. Meclube is an industrial company that produces oil pumping equipment to meet various customer needs. The equipment meets international |
| SEO-лексика | meclube оборудование масла 375 насосы оао густых смазок продукция слива пневматические бар завод получить оборудования оплата смазки различной любых также |
| Безопасность | hsts: ❌, csp: ❌, x_frame: ❌, x_content_type: ❌, re...hsts: ❌, csp: ❌, x_frame: ❌, x_content_type: ❌, referrer_policy: ❌ |
| Доступность | basic: {"missing_alts":17,"empty_links":8}, extend...basic: {"missing_alts":17,"empty_links":8}, extended: {"missing_alts":17,"empty_links":8,"aria_attributes":0} |
| Технологии сайта | Cloudflare, Google Analytics, PHP, React, Yandex M...Cloudflare, Google Analytics, PHP, React, Yandex Metrika, jQuery |
| SSL до | 2026-07-01 |
| Дней до SSL | 35 |
| Кодировка | utf-8 |
| AI-качество | 1 |
| Флаги | {encoding:utf-8} |
| Robots.txt | Открыть robots.txt<html> <head><title>404 Not Found</title></head> <body> <center><h1>404 Not Found</h1></center> <hr><center>nginx/1.18.0 (Ubuntu)</center> </body> </html> <!-- a padding to disable MSIE and Chrome friendly error page --> <!-- a padding to disable MSIE and Chrome friendly error page --> <!-- a padding to disable MSIE and Chrome friendly error page --> <!-- a padding to disable MSIE and Chrome friendly error page --> <!-- a padding to disable MSIE and Chrome friendly error page --> <!- |
| Sitemap | ❌ Нет |
| Соцсети | |
| QR / Короткая ссылка |  niti.by/fgka |